


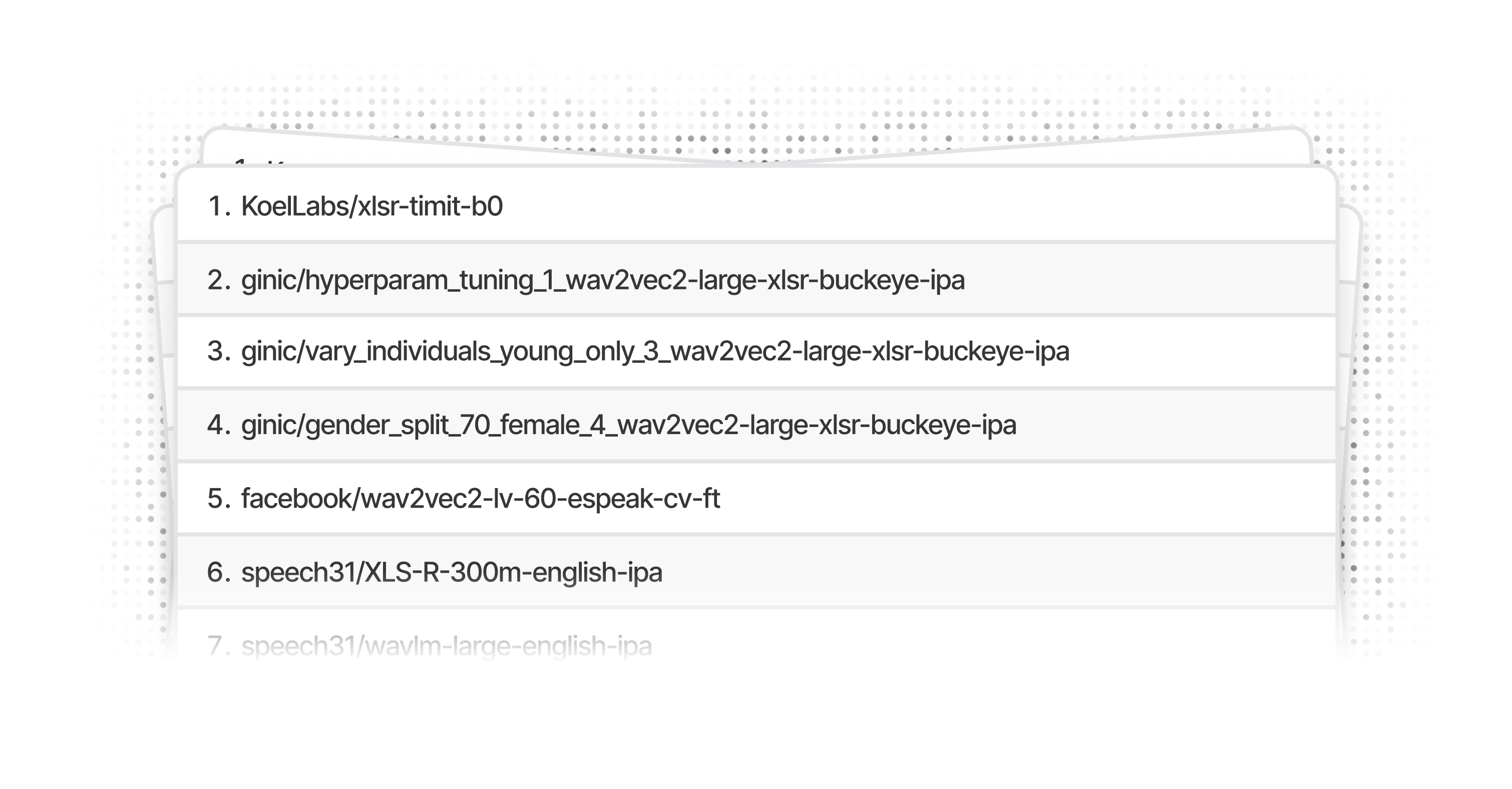
An Introduction
Sometimes, the best machine learning models are hidden in plain sight. During our work on phonemic transcription, we stumbled upon a specialized ginic model that had been finetuned on Facebook's XLSR-53 model using the Buckeye corpus. This discovery proved significant: Ginic performs 1.2x better than Facebook, and iterating on their approach, our model performs 2.2x better than ginic. However, finding this model was more a product of extensive searching than systematic discovery, highlighting a broader challenge in the phoneme transcription space that led us to build this open-source leaderboard.
The Need for Better Model Discovery and Standardized Evaluation
While leaderboards have become fundamental infrastructure in many areas of machine learning - from large language models to automatic speech recognition - the field of phonemic transcription notably lacks such standardized evaluation frameworks. This gap isn't just about missing leaderboards - it reflects a broader absence of unified evaluation standards and comprehensive survey papers that could allow researchers and practitioners to track progress and compare approaches effectively.
A Streamlined Architecture for Open Evaluation
To address this gap, we implemented a system that handles both the queue backend and the leaderboard frontend. This design prioritizes transparency and accessibility - crucial elements often missing in evaluation. Our architecture consists of two main components:
- app.py: Handles the front-end logic using Gradio, providing a clean interface for viewing the leaderboard, checking model status, and submitting new models
- tasks.py: Manages the back-end operations, interfacing with three JSON files in the queue directory:
- leaderboard.json: Stores the final, processed rankings
- tasks.json: Tracks newly submitted models
- results.json: Contains detailed metadata for completed evaluations
Transparency was a key consideration in our design. Unlike some existing leaderboards like Open ASR that require users to request model evaluation and wait, our system automates the process. Most models can be evaluated on the whole test set within hours of submission.
Additionally, the front-end leaderboard and queue backend are visible to all Hugging Face users - a deliberate choice to promote transparency. The results file provides detailed metadata about evaluations and model outputs, allowing users to understand precisely how models perform and evaluations are conducted. that require users to request model evaluation and wait, our system automates the process.
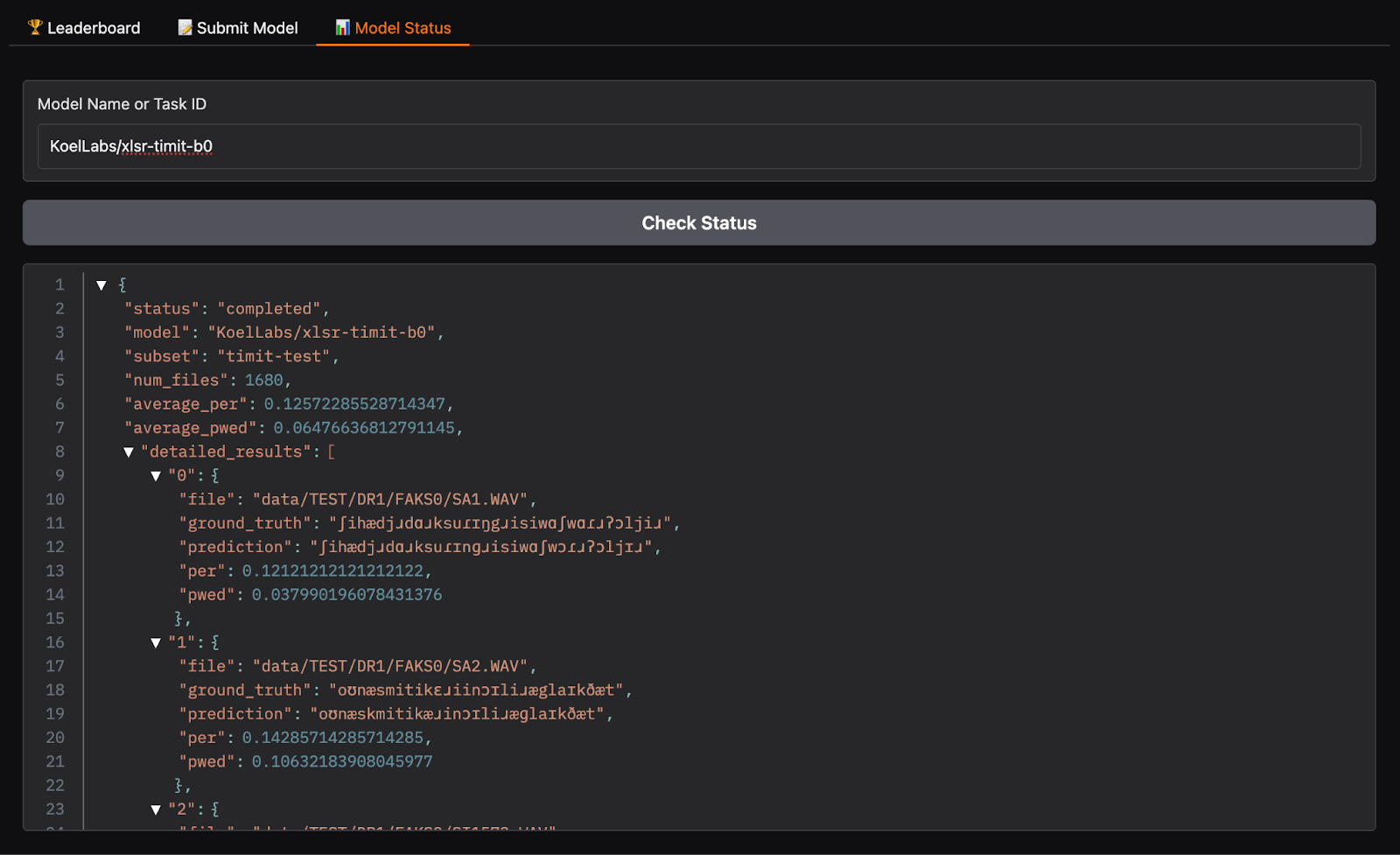
This openness and automation represent a step toward the kind of standardized evaluation infrastructure that has helped accelerate progress in other areas of machine learning but has been notably absent in phonemic transcription.
Technical Implementation Details
Our evaluation system measures model performance using two key metrics:
- PER (Phoneme Error Rate): Calculated using Levenshtein distance between predicted and actual phoneme sequences
- PWED (Phoneme Weighted Edit Distance): A more nuanced metric that considers phonemic feature distances, implemented using the panphon library
You can read more about these evaluation methods in our blog post here.
We use the TIMIT speech corpus as our evaluation dataset, providing a standardized benchmark widely recognized in the speech recognition community. The evaluation runs on a consistent compute environment (16GB RAM, 2vCPUs) to ensure reproducibility.
We Need More of These Projects
The success of platforms like the Open LLM Leaderboard, with nearly 3,000 submissions, demonstrates the community's appetite for transparent model comparison. While some argue that gamifying model development could lead to metric gaming, we've seen how leaderboards can transform competition into collaboration. They provide standardized benchmarks, foster innovation through transparency, and create an engaging entry point for newcomers to the field. Most importantly, they help surface promising but lesser-known models that might otherwise remain undiscovered.
Looking Forward
Creating leaderboards has historically been challenging, with many templates becoming quickly outdated. Hugging Face has recently streamlined this process through their Space SDK, which is ideal for evaluating models of varying sizes and computational requirements. To create a leaderboard using their template:
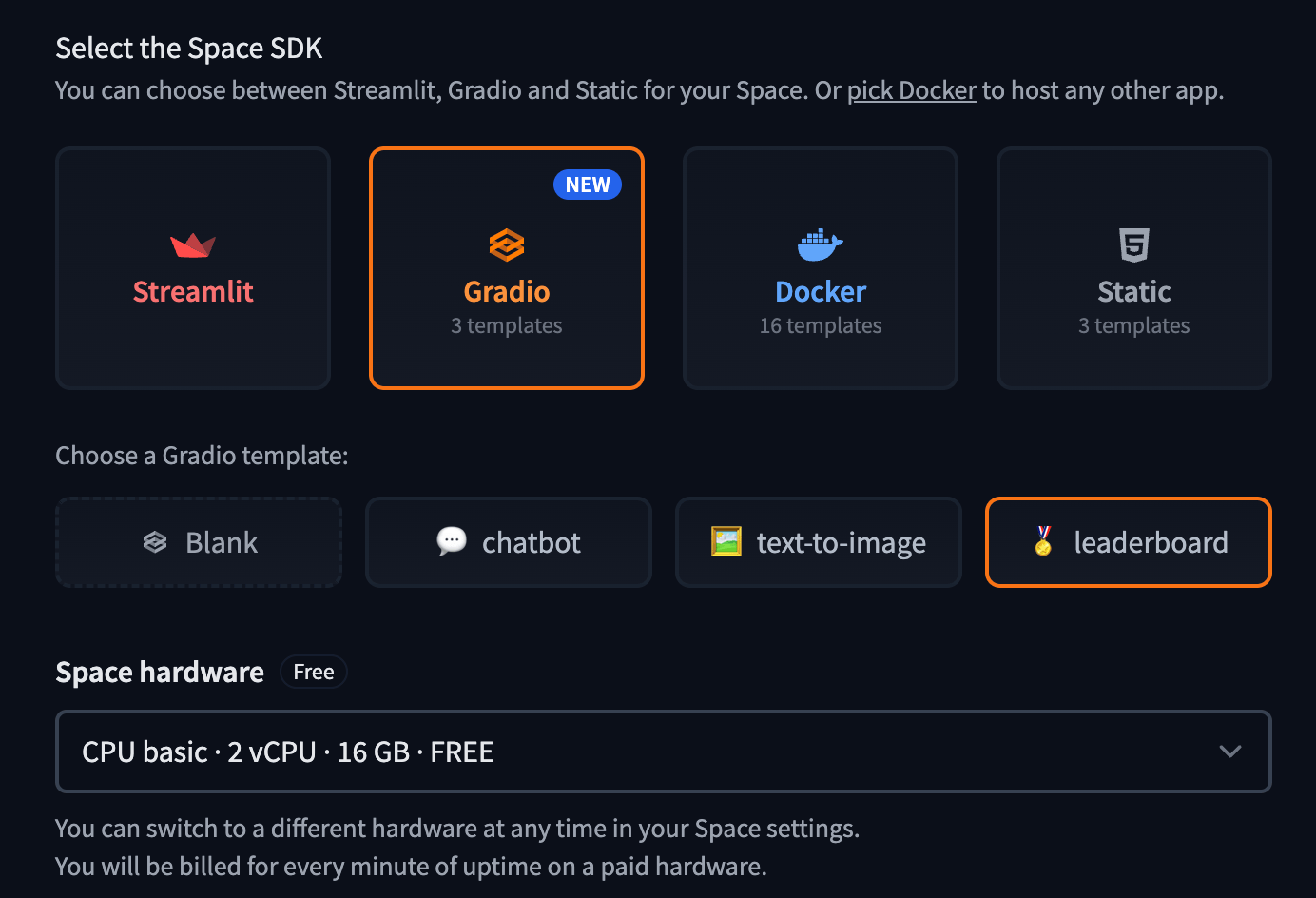
- Navigate to https://huggingface.co/new-space
- Select "Space SDK" as the template type
- Choose "Gradio" as the framework
- Select "Leaderboard" from the template options
- You will be asked for an access token in the UI before you create the space. This can be created in your settings and needs read access for the leaderboard to function.
For evaluating collections of smaller models that don't require extensive pre-testing, our lightweight implementation offers a practical working example. It demonstrates a complete end-to-end leaderboard system while maintaining simplicity in both setup and maintenance. We've made our codebase publicly available - feel free to duplicate it for your own specialized evaluation needs or use it as a reference implementation when building more complex systems. We are actively working on adding more evaluation datasets/metrics and support for more model architectures and welcome contributions!
The path to better model evaluation shouldn't be blocked by infrastructure complexity. Whether using Hugging Face's template or our simpler architecture, the goal remains the same: making model discovery and comparison more accessible to the community.